天下难事,必作于易。机器学习作为一个有广泛研究范围和应用范围的领域,要在整个领域有很深的造诣是十分困难的一件事情,一个好的途径是先去了解和掌握概况,然后再去选择感兴趣的研究方向。要做到前面这一点,根据我一贯认同的“总览-掌握-超越”三步走的方法,应该是能相对容易地达成,所以也就首先有了这个机器学习的总览篇第一篇文章,后续会继续分享有监督学习篇、深度学习篇(由于内容丰富故单独一篇)、强化学习篇、无监督学习篇、半监督学习篇这五篇,每一篇会包含10篇以内的文章,文章宗旨是简明扼要、博采众长。
本文首发于我的知乎专栏《机器怎么学习》中 机器学习·总览篇(1) 机器学习的定义和类别,转载请保留链接 ;)
一、机器学习的定义
从wiki上,我们能了解到的机器学习定义如下:
- 定位: 机器学习属于人工智能的一个分支,也是实现人工智能的一个途径,即以机器学习为手段解决人工智能中的问题
- 学科: 机器学习是一门多领域交叉学科,涉及概率论、统计学、逼近论、凸分析、计算复杂性理论等多门学科
- 研究范围: 机器学习理论主要是设计和分析一些让计算机可以自动“学习”的算法。机器学习算法是一类从数据中自动分析获得规律,并利用规律对未知数据进行预测的算法。
总的来说,机器学习是实现人工智能的一类重要的方法集合。
从我一个程序员的视角来看,传统编程方式和机器学习的差别可用图1表示,
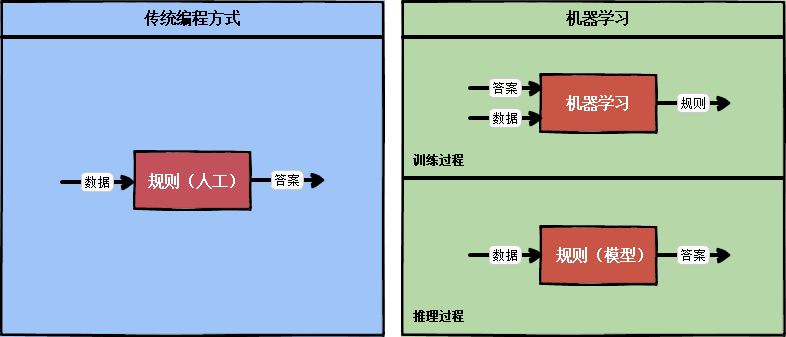
传统编程方式是一个推理的过程,编写人工规则,输入数据,给出答案;相比较而言,机器学习多了一步训练过程,输入数据和答案,给出规则,然后再走推理过程。
二、机器学习的类别
人工智能和机器学习的关系可用图2表示,
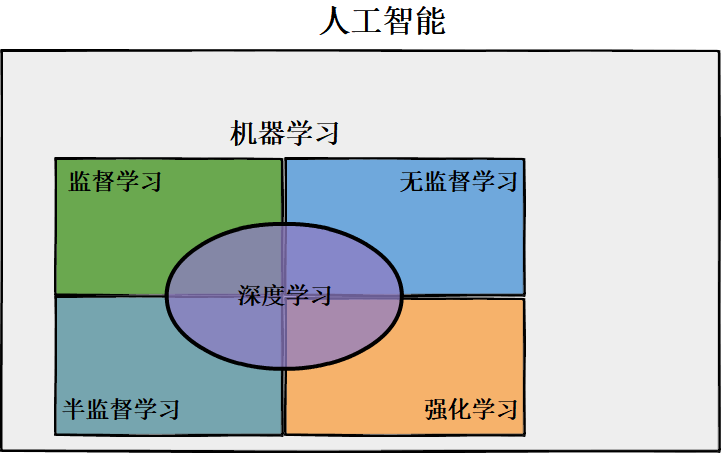
人工智能和机器学习的分类可用图3表示,
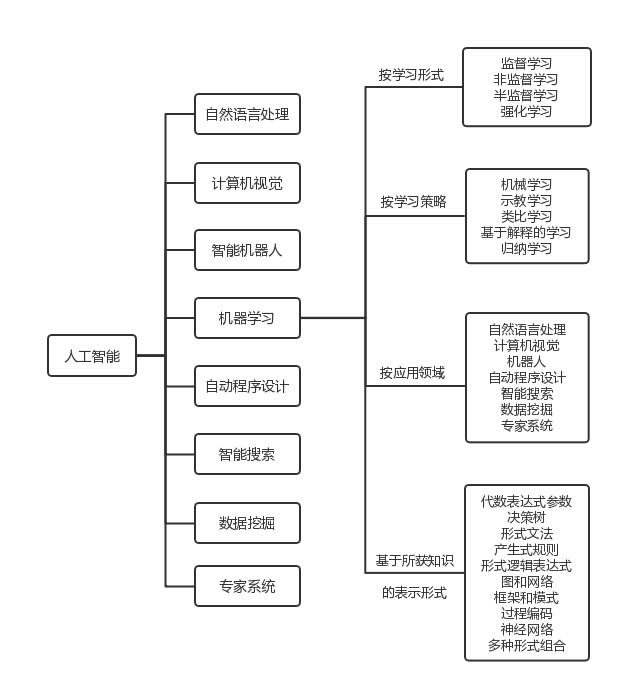
在图3中,对于机器学习具体来说,分类详情如下:
按学习形式分类
-
监督学习:给定数据,预测标签
-
无监督学习:给定数据,寻找隐藏的结构,比如判定潜在类别(聚类)或者改变表征形式(降维)
-
半监督学习:介于监督和非监督之间的学习方式,通常目标也是预测标签
-
强化学习:给定数据,学习如何选择一系列行动,以最大化特定目标的收益
按学习策略分类
-
机械学习(Rote learning):学习者无需知识转换和任何推理,直接吸取环境所提供的信息。想象你有的一个C语言的Hashmap,以环境信息为key值,以目标动作为value值,根据以往的key-value信息对来直接调整Hashmap里的值。一个典型应用例子是第二篇会介绍的一个机器学习历程中的重要事件-Samuel的跳棋程序。
-
示例学习(Learning from instruction):学习者吸取环境所提供的信息,将知识转换成内部可使用的表示形式,并将新知识和旧知识有机地结合。整个过程环境仍需要做大量工作,而推理过程占小部分。
-
类比学习(Learning by analogy):学习者利用两个不同领域中(源域和目标域)的知识相似性,通过类比,从源域的知识推导出目标域的相应知识。类比学习相比与机械学系和示例学习,要求更多的推理。人类科学技术发展过程中,许多科学发现就是通过类比学习实现的,例如著名的卢瑟福类比就是通过将原子结构(目标域)同太阳系(源域)作类比,揭示了原子结构的奥秘。另外,机器学习中重要的迁移学习也是基于该策略
-
基于解释的学习(Explanation-based learning,EBL):分两步走,先构造一个解释来说明为什么某个例子满足目标概念,然后将解释推广为目标概念的一个满足可操作准则的充分条件。这种学习方式我感觉很接近程序员(比如我自己)找程序bug和优化代码的常用方法。而事实上,EBL也是被广泛应用于知识库求精和改善系统的性能
-
归纳学习:学习者通过环境提供某概念的一些实例或反例,通过归纳推理出该概念的一般描述。这种学习的推理工作量远多于示教学习和演绎学习,因为环境并不提供一般性概念描述(如公理)。从某种程度上说,归纳学习的推理量也比类比学习大,因为没有一个类似的概念可以作为”源概念”加以取用。归纳学习是最基本的,发展也较为成熟的学习方法,在人工智能领域中已经得到广泛的研究和应用。
按应用领域分类
-
自然语言处理=文本处理+机器学习:在自然语言处理技术中,大量使用了编译原理相关的技术,比如词法分析,语法分析等等(我记得本科上编译原理这门课的时候,一起听课还有中文学院的同学)。除此之外,在语义理解这个层面,则广泛使用了机器学习等技术
-
计算机视觉=图像处理+机器学习:与自然语言处理类似的划分,图像处理技术用于将图像处理为适合进入机器学习模型中的输入,机器学习则负责从图像中识别出相关的模式
-
机器人=机械控制+机器学习:传统的机器人,比如仿真步行的腿足式机器人,实现方法依赖于硬件平台和传统运动控制方法,其中硬件平台包括高水平的液压元件与机电系统,运动控制方法包括二次规划(Quatratic Programming)和模型预测控制(Receding Horizon Control),波斯顿动力就是业界领先的标杆。而目前实验室中的运动控制通常是采用机器学习(主要是强化学习)来实现的,比如OpenAI在他的OpenAI Gym上有很多用于机器人模拟训练的仿真环境,用于评测不同的强化学习算法。总的来说,目前机器学习在真实环境中的机械机器人上还是难堪重任
-
自动程序设计=程序语言处理+机器学习:程序也就是计算机语言,它与自然语言对应。自动程序设计只需要用户陈述他的问题而不必提出精确的解题算法,应用机器学习能够在语义层面上更好地实现这个从“需求”到“程序”的过程。
-
智能搜索=信息索引算法+机器学习:
-
数据挖掘=数据库+机器学习:用机器学习的方法而不是人工规则的方法去数据库中“挖掘”到有效信息
-
专家系统=专家水平的知识+机器学习:一部分置信度很高的专家水平的知识作为先验知识,结合机器学习进行更准确的推理和判断
基于获取知识的表示形式分类
-
代数表达式参数:学习的目标是调节一个固定函数形式的代数表达式参数或系数来到达一个理想的性能,以游戏AI设计为例,当敌我双方的状态满足条件{a攻击比+b护甲比+c*血量比>1}时就逃跑,通过数据的调优,获取一个合适的a,b,c
-
决策树:主要是针对决策树模型,学习的目标是学习每个节点的划分属性和阈值
-
形式文法:主要是在自然语言或者程序语言学习领域,学习目标是该语言的形式文法
-
产生式规则:更多是用于专家系统,表达式是P->Q,形式很简单,但它并不是简单的if/then语句:if的条件是精确匹配,而产生式规则的前件(P)可以是模糊匹配;then的执行是立即确定会执行的,而产生式规则的后件(Q)并不是满足前件就立即执行,能否执行还取决于冲突消解策略,比如同时满足多个规则之后的优先级选择
-
形式逻辑表达式:基本成分是命题、谓词、变量、约束变量范围的语句,及嵌入的逻辑表达式。基本成分可以理解成我们看论文时经常看到的数学公式,而嵌入的逻辑表达式则是其中的“where, n=0,1,2…”
-
图和网络:生成的是一个图结构,有的系统采用图匹配方法来有效地比较和索引知识
-
框架和模式:每个框架包含一组槽,用于描述事物(概念和个体)的各个方面,感觉可以理解成一个类或者hashmap结构
-
计算机程序:主要是针对自动程序设计,学习的目的在于取得一种能实现特定过程的能力,而不是为了推断该过程的内部结构
-
神经网络:主要是针对神经网络模型的应用场景中
-
多种形式组合。以上几种表示形式的组合
三、小结
总的来说,
-
机器学习的定位是什么?很简单,就是实现人工智能的一种工具
-
机器学习这种工具有怎样性质?一种在确定编程之外给予计算机以学习能力(Arthur Samuel 1959)
-
机器学习程式化定义?一个程序从经验E中学习,解决任务T,达到性能度量值P,实现的方法当且仅当,有了经验E后,经过P评判,程序在处理T时的性能有所提升(Tom Mitchell 1998)这个定义实际上也合理描述了机器学习的实现过程
参考文献
- wiki: 机器学习
- 知乎:有监督学习、无监督学习以及强化学习
- CSDN博客:【吴恩达机器学习笔记】001 什么是机器学习(What is Machine Learning)
- CSDN博客: 机器学习综述——机器学习理论基础与发展脉络