在机器学习中,逻辑回归模型是一种十分常用且有效的线性分类器,它在1958年被 Cox 正式命名,当时被用于解决美国人口普查任务。本文将从 公式推导、代码实现 以及 它的 “家族” 广义线性模型 三个方面对逻辑回归模型进行介绍。
文章首发于我的博客,转载请保留链接 ;)
一、逻辑回归(Logistic regression)
逻辑回归,即 Logistic Regression,名字的由来是因为算法流程中使用到了一个关键的 Logisitic 函数,该函数是一个比较简单的单调递增函数,表达式如下,
该函数也称作 sigmoid 函数,逻辑回归用 sigmoid 函数来计算样本对应的后验概率,它的函数曲线如下图所示,
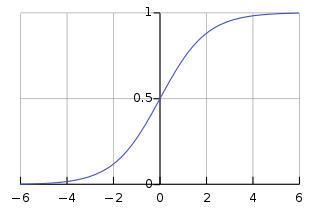
本文第一节接下来就是介绍逻辑回归是怎么使用 sigmoid 函数作为后验概率计算式来达到分类这一目的的。
1.1 代价函数公式推导
对于一个二分类任务,LR 公式推导可表示如下,
- 公式 (1) 中直接将自变量 x,即特征,通过 h(x) 这一 sigmoid 函数表示(这么表示的原因在本文第二节说);因变量 y 等于1的概率是 h(x),为0的概率当然是 1-h(x);
- 公式 (2) 用一个公式涵盖了公式 (1) 中的两个式子;
- 再假设每个样本互相独立,利用极大似然估计已知有公式 (3) 成立;
- 将公式 (2) 代入公式 (3) 中,得到似然估计函数的表示 (4) ;
- 为了将指数运算去掉,等式两边取 log 得到公式 (5) ;
- 目的是使似然估计函数最大,而代价函数的目的是最小,所以在公式 (5) 上加个负号,得到公式 (6) 的代价函数表示。
其中值得一提的是,交叉熵可以用来衡量两个分布的相似度情况,假设已知
,那么我们衡量 p 和 q 这两个分布的相似度就可以通过交叉熵公式来计算,
我们发现上面交叉熵公式跟之前的逻辑回归代价函数完全一致,也就是说逻辑回归的代价函数其实就是交叉熵。求得代价函数后,接下来的任务就是最小化代价函数,常见的方法就是梯度下降法,梯度公式推导如下,
每轮对参数的迭代通常除以样本量,即
我们会发现逻辑回归的参数梯度公式如此简单。值得注意的是,这里的参数 theta 是包含 wx+b 中的 w 和 b 的,也就是说 x 的组成为 (x1, x2, …, xn, 1):其中 x1 到 xn 是特征维度,对应乘以 w 中的每一维,1 对应乘以 b。
二、LR 的 Python 实现
还是使用垃圾信息分类任务为例,选用的数据集是经典的 SMS Spam Collection v. 1,共5,574条短信,其中垃圾短信747条,非垃圾短信4827条。“SMS Spam Collection v. 1” 数据集格式如下所示,
1. ham MY NO. IN LUTON 0125698789 RING ME IF UR AROUND! H*
2. ham Siva is in hostel aha:-.
3. spam FreeMsg: Txt: CALL to No: 86888 & claim your reward of 3 hours talk time to use from your phone now! ubscribe6GBP/ mnth inc 3hrs 16 stop?txtStop
4. ham Cos i was out shopping wif darren jus now n i called him 2 ask wat present he wan lor. Then he started guessing who i was wif n he finally guessed darren lor.
5. spam Sunshine Quiz! Win a super Sony DVD recorder if you canname the capital of Australia? Text MQUIZ to 82277. B
每个样本一行,上面的示例一共有5个样本。1、2、4属于正样本,即正常消息,标签是”ham”;3、5属于负样本,即广告等垃圾消息,标签是”spam”。标签后面就是具体的消息内容。
2.1 不使用机器学习库的 numpy 实现
本小节就只用 numpy 库实现手机短信垃圾(SMS Spam)分类。
1.2.1 特征提取
特征提取的第一步是将句子切分成单词,由于是英文,所以这里处理方式比较简单暴力,按照空格和除’之外的符号来切分了,然后全部转小写。用热编码特征,每个维度值表示对应的单词是否出现,出现的单词对应特征为1,未出现的单词对应特征为0,特征提取这部分代码如下所示,
def feature_batch_extraction(d_list, kw_set):
"""
特征批量提取
:param d_list: 原始数据集
:param kw_set: 关键字列表
:return:
"""
kw_2_idx_dict = dict(zip(list(kw_set), range(len(kw_set))))
feature_data = np.zeros((len(d_list), len(kw_set)))
label_data = np.zeros((len(d_list), 1))
for i in range(len(d_list)):
label, words = d_list[i]
for word in words:
if word in kw_2_idx_dict:
feature_data[i, kw_2_idx_dict[word]] = 1
label_data[i] = 1 if label == 'spam' else 0
return feature_data, label_data
默认热编码特征所有维度的值都是0,特征提取整个过程就是将每个样本的单词集合遍历一遍,单词对应的关键字置为1。
1.2.2 训练
训练的过程就是将 1.1 节推导出的公式用代码实现一遍,训练目的就是求得模型参数 W 的最优解,可以使得代价函数值最小,
class RegressionModel(object):
"""
逻辑回归模型
"""
def __init__(self):
self.W = None
def train(self, x_train, y_train, learning_rate=0.1, num_iters=10000):
"""
模型训练
:param x_train: shape = num_train, dim_feature
:param y_train: shape = num_train, 1
:param learning_rate
:param num_iters
:return: loss_history
"""
num_train, dim_feature = x_train.shape
# w * x + b
x_train_ = np.hstack((x_train, np.ones((num_train, 1))))
self.W = 0.001 * np.random.randn(dim_feature + 1, 1)
loss_history = []
for i in range(num_iters+1):
# linear transformation: w * x + b
g = np.dot(x_train_, self.W)
# sigmoid: 1 / (1 + e**-x)
h = 1 / (1 + np.exp(-g))
# cross entropy: 1/m * sum((y*np.log(h) + (1-y)*np.log((1-h))))
loss = -np.sum(y_train * np.log(h) + (1 - y_train) * np.log(1 - h)) / num_train
loss_history.append(loss)
# dW = cross entropy' = 1/m * sum(h-y) * x
dW = x_train_.T.dot(h - y_train) / num_train
# W = W - dW
self.W -= learning_rate * dW
# debug
if i % 100 == 0:
print('Iters: %r/%r Loss: %r' % (i, num_iters, loss))
return loss_history
用整个训练集的所有样本来求梯度下降值,然后迭代执行 num_iters 次。
1.2.3 验证
最后,用准确率和混淆矩阵两个指标来进行验证,评价训练好的模型的表现效果,
class RegressionModel(object):
"""
逻辑回归模型
"""
def __init__(self):
self.W = None
def validate(self, x_val, y_val):
"""
验证模型效果
:param x_val: shape = num_val, dim_feature
:param y_val: shape = num_val, 1
:return: accuracy, metric
"""
num_val, dim_feature = x_val.shape
x_val_ = np.hstack((x_val, np.ones((num_val, 1))))
# linear transformation: w * x + b
g = np.dot(x_val_, self.W)
# sigmoid: 1 / (1 + e**-x)
h = 1 / (1 + np.exp(-g))
# predict
y_val_ = h
y_val_[y_val_ >= 0.5] = 1
y_val_[y_val_ < 0.5] = 0
true_positive = len(np.where(((y_val_ == 1).astype(int) + (y_val == 1).astype(int) == 2) == True)[0]) * 1.0 / num_val
true_negative = len(np.where(((y_val_ == 0).astype(int) + (y_val == 0).astype(int) == 2) == True)[0]) * 1.0 / num_val
false_positive = len(np.where(((y_val_ == 1).astype(int) + (y_val == 0).astype(int) == 2) == True)[0]) * 1.0 / num_val
false_negative = len(np.where(((y_val_ == 0).astype(int) + (y_val == 1).astype(int) == 2) == True)[0]) * 1.0 / num_val
negative_instance = true_negative + false_positive
positive_instance = false_negative + true_positive
metric = np.array([[true_negative / negative_instance, false_positive / negative_instance],
[false_negative / positive_instance, true_positive / positive_instance]])
accuracy = true_positive + true_negative
return accuracy, metric
其中,accuracy 是模型准确率,metric 是混淆矩阵;如果把垃圾邮件当作正样本,正常邮件当作负样本,那么 true_positive 是将垃圾信息判定成垃圾信息(正样本判定成正样本)的概率;true_negative 是将正常信息判定成正常信息(负样本判定成负样本)的概率;false_positive 是将正常信息判定成垃圾信息(负样本判定成正样本)的概率,又称虚警率(False Alarm);false_negative是将垃圾信息判定成正常信息(正样本判定成负样本)的概率,又称漏警率(Missing Alarm)。
完整代码见 https://github.com/KangCai/Machine-Learning-Algorithm/blob/master/logistic_regression.py
2.2 scikit-learn 实现
scikit-learn 库同样提供了很简单的调用接口,
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(X, Y)
result_predict = lr.predict(X')
2.3 交叉验证结果
通过 2.1 的代码实现,设定关键字的个数为200、500、2000、5000、7956这5种情况,训练过程中收敛情况如下图所示,
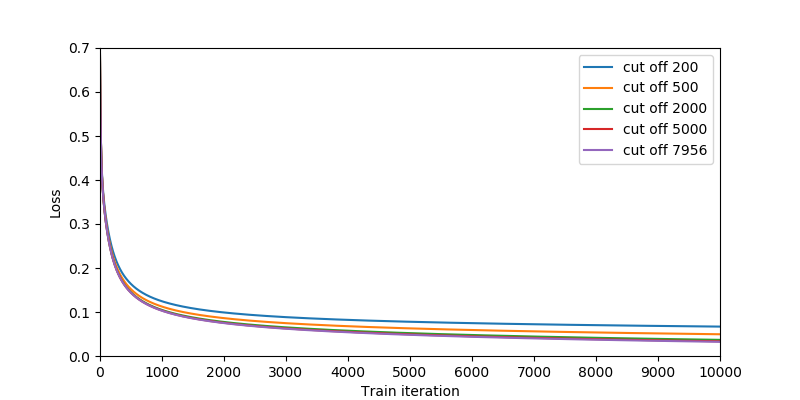
可以看到关键字越多,特征维度越高,收敛速度越慢,但最终loss越低,符合理论预期:因为特征维度越高,参数越多,收敛速度越慢,拟合程度也越高。为了测试模型的预测准确率,对数据集做4折-交叉验证,准确率为
| 200 | 500 | 2000 | 5000 | 7956 | |
|---|---|---|---|---|---|
| 准确率 | 97.8% | 98.3% | 98.5% | 98.5% | 98.4% |
| 时间(秒) | 8.4 | 23.2 | 95.3 | 241.0 | 316.6 |
从上表可以看到,特征维度越高,即参考的单词越多,准确率是呈增加趋势的,当然耗时也会随之线性增加。但需要注意一点,即使本实验采取的是交叉验证方式,这也只能证明高维度特征的朴素贝叶斯模型针对本数据集是有效的,对于新数据不一定有效,即不一定具有很强的泛化能力。特征维度为7956时的准确率反而低于5000特征维度的准确率,表明去掉一些尾部低频单词能在一定程度上降低噪声数据干扰。
对于同样的任务和数据集,与下面列出的朴素贝叶斯模型的表现效果对比,
| 200 | 500 | 2000 | 5000 | 7956 | |
|---|---|---|---|---|---|
| 准确率 | 97.5% | 97.9% | 97.0% | 95.7% | 95.5% |
| 时间(秒) | 0.3 | 0.6 | 2.5 | 4.7 | 4.9 |
逻辑回归模型获得了更高的准确率,但在时间效率方面,远远不及朴素贝叶斯模型。
另外,为了进一步地研究逻辑回归模型针对垃圾消息分类任务的适用性,下面列出了当特征维度为 5000 时的混淆矩阵,
| 判成正常 | 判成垃圾 | |
|---|---|---|
| 正常 | 100% | 0% |
| 垃圾 | 11.3% | 88.7% |
可以看到正常消息判成正常的概率是100%,而垃圾消息会有一小部分会判成正常,正常消息被阻挡的情况是用户不能接受的,而一小部分的垃圾消息没有被阻挡掉在一定程度是可以理解的,因此这种混淆矩阵情况对于实际应用是相当适合的。
二、广义线性模型(Generalize linear model)
为什么逻辑回归会选择使用 sigmoid 函数,而不使用其它函数呢?有很多其它文章说是因为 sigmoid有很多优秀的性质,这其实是本末倒置了,具备 sigmoid 函数类似性质的函数有很多。之所以逻辑回归使用 sigmoid 函数,其实是与 “逻辑回归模型对数据特定的先验分布假设” 直接相关的。下面将从指数分布族,到广义线性模型,再到联结函数进行介绍。
2.1 指数分布族(Exponential family of distributions)
概率分布函数是概率论的基本概念之一,常见的离散型随机变量分布模型有“0-1分布”、二项式分布、泊松分布等;连续型随机变量分布模型有均匀分布、正态分布等。
在所有类型的概率分布中,有一类被称为指数分布族的有特定共同表示形式的分布。指数分布族在上世纪30年代中期被提出,它作为统计中最重要的参数分布族,为很多重要而常用的概率分布提供了统一框架。该类概率分布函数可表示为如下形式,
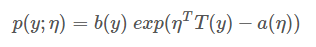
其中,

大多数的概率分布都属于指数分布族:
- 伯努利(Bernoulli)分布:对 0、1 问题进行建模;
- 二项(Multinomial)分布:对 K 个离散结果的事件建模;
- 泊松(Poisson)分布:对计数过程进行建模,比如网站访问量的计数问题,放射性衰变的数目,商店顾客数量等问题;
- 高斯(Gaussian)分布:即正态分布;
- gamma 分布与指数(exponential)分布:对有间隔的正数进行建模,比如公交车的到站时间问题;
- β 分布:对小数建模;
- Dirichlet 分布:对概率分布进建模;
- Wishart 分布:协方差矩阵的分布。
不属于指数分布族的概率分布有:均匀分布、学生t-分布(Student’s t-distribution)等。
2.2 联结函数
广义线性模型是线性模型的扩展,完成这一扩展靠的就是联结函数:建立因变量数学期望值与自变量线性组合之间的关系。 广义线性模型通过采用对应的联系函数针对不同 y 分布的数据,让y的取值范围与预测值范围一致,以及让模型比较好地拟合当下的数据,为了达到这个目的,广义线性模型做了如下 3 个设定,

本文不深究这 3 个设定从何而来,只讨论从这 3 个设定能得到怎样的学习算法。下面以逻辑回归模型和线性回归为例。
2.2.1 逻辑回归和联结函数
针对二分类问题,一种常见的方法就是逻辑回归模型,如下图所示,

假设样本后验概率是 y,逻辑回归模型是 y 服从伯努利分布下的广义线性模型,对应的联结函数是 sigmoid 函数,推导过程如下所示,
逻辑回归用于解决二分类问题,对于二分类问题很自然想到 y 服从伯努利分布,概率符合
,因此有
,参照如下指数分布族的标准形式
,可以得到
又由于广义线性模型的第三个假设 ,故
得到是sigmoid函数。这样就将概率和 sigmoid 函数结合起来了。
2.2.2 线性回归和联结函数
针对线性回归问题,最常用的方法是最小二乘法,它的优化目标是使得偏差的平方和最小,如下图所示,
使用最小二乘法的线性回归模型可以看成是 y 服从高斯分布下的广义线性模型,对应的联结函数是线性函数,推导过程如下,从线性回归样本 y 服从高斯分布出发,可以得到
同样地,参照指数分布族的标准形式,可以得到:
再根据广义线性模型的第二、三个假设条件,即可得到线性回归模型的联结函数,
综上所述,广义线性模型是通过假设一个概率分布并将其化成指数分布族形式,通过不同概率对应的不同的联结函数,来得到不同的模型来拟合不同的数据分布情况。