从基本理论上看,如前一篇介绍统计推断的文章所说,统计推断是机器学习十分重要的理论基础,所以机器学习狭义上就是指代统计学习方法;从方法框架上看,机器学习(统计学习方法)的组成有三个要素:模型、策略和算法。我们通常接触到的所谓“深度学习”、“支持向量机”、“罗吉斯蒂克回归”、“决策树”等等,都离不开这三要素。毫不夸张的说,学习机器学习的关键,就是掌握它这三个要素。
本文首发于我的知乎专栏《机器怎么学习》中 机器学习·总览篇(4) 机器学习的三要素,转载请保留链接 ;)
一、机器学习的三要素
数据在机器学习方法框架中的流动,会按顺序经历三个过程,分别对应机器学习的三大要素:1. 模型;2. 策略;3. 算法
-
模型:谈到机器学习,经常会谈到机器学习的“模型”。在机器学习中,模型的实质是一个假设空间(hypothesis space),这个假设空间是“输入空间到输出空间所有映射”的一个集合,这个空间的假设属于我们的先验知识。然后,机器学习通过“数据+三要素”的训练,目标是获得假设空间的一个最优解,翻译一下就是求模型的最优参数。
-
策略:在模型部分,机器学习的学习目标是获得假设空间(模型)的一个最优解,那么问题来了,如何评判优还是不优?策略部分就是评判“最优模型”(最优参数的模型)的准则或方法。
-
算法:在策略部分,机器学习的学习目标转换成了求目标函数的最小值,而算法部分就是对函数最优解的求解方法。
三者关系如下图所示,
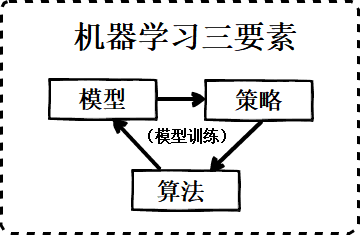
特征通过模型得到值和标签(ground truth)通过一定的策略形成对模型参数的评判标准,再 根据评判标准、通过优化算法 优化模型参数,从而达到模型训练的目的。
二、模型
2.1 判别模型和生成模型
一般来说,机器学习模型会分为判别模型(Discriminative Model)和生成模型(Generative Model)两类。
判别模型相对来说更常用,感知机(Perceptron)、罗吉斯蒂克回归(LR)、支持向量机(SVM)、神经网络(NN)、K近邻(KNN)、线性判别分析(LDA)、Boosting、条件随机场(CRF)模型都属于判别模型。判别模型本身又分为两类:
(1)直接对输入空间到输出空间的映射建模;
(2)分两步,先对条件概率P(y|x)建模,再分类。
生成模型是一种更加间接的建模,高斯判别分析(GDA)、朴素贝叶斯(NB)、文档主题生成模型(另外一个LDA,跟线性判别分析的LDA是完全不同的两个概念)、受限玻尔兹曼机(RBM)、隐马尔科夫模型(HMM)属于生成模型。分三步:先对联合概率P(x,y)建模,再根据贝叶斯公式算出P(y|x),最后再分类。
以上提到了很多种当前热门的机器学习模型,不了解不要紧,在后面的文章都会一一详细介绍。为了方便起见,后文提到的某些模型的名称用惯用简写来表示。这里有必要提一下近些年来大热的深度学习,深度学习其实只是机器学习的一个大派别,深度神经网络模型(DNN)也只是众多机器学习模型中的一类:卷积神经网络(CNN)、循环神经网络(RNN)、多层感知机(MLP)、堆叠自编码器(SAE)、堆叠受限玻尔兹曼机(有一个专门名字深度置信网络,DBN),以及以上各种模型的变形和扩展,它们都是针对特定的问题和当前的高性能计算时代而诞生,没必要神化。
回到判别模型和生成模型,两者的差别就在于是否先对联合概率P(x,y)建模。学术界对两种模型各自都有不同的声音,主要是针对求条件概率P(y|x)的方法应该直接建模还是用P(x,y)间接建模有分歧:SVM之父Vapnik的观点是生成模型的第一步是先对联合概率P(x,y)建模,这个做法没必要,对P(y|x)直接进行建模就行了,事实上这是学术界主流认识;而Andrew Ng为生成模型发声,他认为对P(x,y)进行建模从而达到判别的目的也有它自身的一些优势:虽然生成模型的渐进误差(Asymptotic error)确实是比判别模型的大,但随着训练集增加后,生成模型会比判别模型更快得达到渐进误差(收敛速度更快)。
2.2 概率模型和非概率模型
还有一种常用的分类方式,将判别模型(2)方法即先求条件概率的方法和生成模型先求联合概率的方法作为一类,称之为概率模型;将判别模型(1)方法即直接建模的方法分为另一类,称之为非概率模型。
概率模型由条件概率分布P(y|x)表示。所有生成模型都是概率模型,除此之外,判别模型中的LR、条件随机场(CRF)等属于概率模型。概率模型指出了学习的目的是学出联合概率P(x,y)或条件概率P(y|x),其中联合概率通过贝叶斯公式P(x,y)=P(x|y)P(y)拆分成P(x|y)和P(y)分别进行估计。无论是P(y|x)、P(x|y)还是P(y),都是会先假设分布的形式,例如LR就假设了 y|x 服从伯努利分布,线性回归假设了误差项服从均值为0的高斯分布。
非概率模型由决策函数y=h(x)表示。判别模型中感知机、SVM、神经网络、KNN都属于非概率模型。
两者的差别就是是否直接对输入空间到输出空间建模。概率模型相对而言包含的信息量比非概率模型多,而且更加精细,所以当具有足够数据准确描述不确定参数的概率分布特性时,概率模型更为适用;非概率模型对已知数据的要求低,它只需要确定不确定参量的界限,而不要求其具体的分布形式,且计算过程通常更简便,所以当在掌握的原始数据较少的情况下,非概率模型更合适。
三、策略
了解机器学习的策略,最关键是掌握10个名词:欠拟合(Underfitting)、过拟合(Overfitting)、经验风险(Empirical risk)、经验风险最小化(Empirical risk minimization, ERM)、结构风险(Structural risk)、结构风险最小化(Structural risk minimization, SRM)、损失函数(Loss function)、代价函数(Cost function)、目标函数(Object function)、正则化(Regularization)
为了理解这些名词,我们从一个例子开始说起,如图1所示,
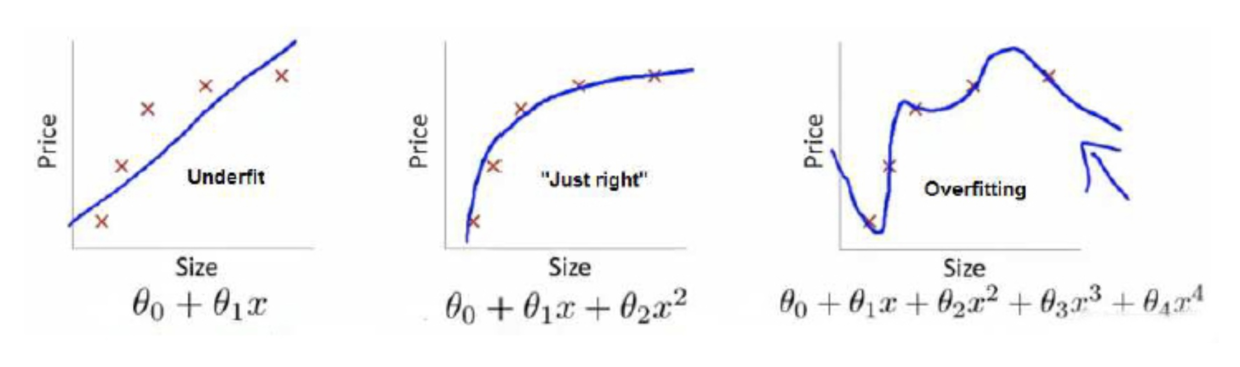
其中,蓝色的线为训练出的模型,红叉是样本。从图1中可以看到,第1个子图中的模型没有很好的拟合样本,这种情况就叫做欠拟合(Underfitting),欠拟合的问题在于无法很好地拟合当前训练样本。
为了避免欠拟合的问题,需要有一个标准来表示拟合的好坏,通常用一个函数来度量拟合的程度,比如常见的平方损失函数(Square loss function),图2是对某一个样本得拟合程度函数,
图2的这个函数就称为损失函数(loss function),是常见损失函数的一种。损失函数越小,就代表模型对某个样本拟合得越好。期望风险函数是损失函数的期望,这是由于我们输入输出遵循一个联合分布,但是这个联合分布是未知的,所以无法计算。但是我们是有历史数据的,就是我们的训练集,关于训练集的平均损失称作经验风险(Empirical risk),我们常用经验风险替代期望风险,因为根据大数定理,当样本容量趋于无穷时,经验风险也就趋于期望风险,经验风险可表示为,
我们希望经验风险最小,称为经验风险最小化(Empirical risk minimization, ERM),而这个度量经验风险的函数称为代价函数(Cost function)。
如果到这一步就完了的话,那我们看上面的图1,那肯定是第3个子图的经验风险函数最小了,因为它对历史的数据拟合的最好嘛。但是我们从图上来看。肯定不是最好的,因为它过度学习历史数据,导致它在真正预测时效果会很不好,比如此时右上方按照目前的趋势再有一堆新样本,该模型就废掉了,这种情况称为过拟合(Overfitting)。为什么会造成这种结果?大白话说就是它的函数太复杂了,都有四次方了,这就引出了下面的概念,我们不仅要让经验风险最小化,还要让结构风险最小化。这个时候就定义了一个度量函数
,这个函数专门用来度量模型的复杂度,表示模型的结构风险(Structural risk),在机器学习中也叫正则化(Regularization),为了让模型尽可能结构简单,我们的优化目的又多一个,即结构风险最小化(Structural risk minimization)。常用的正则化方法有L1范数和L2范数,在机器学习中正则化使用得极其广泛,以后的文章会进行详细介绍。到了这一步,我们就可以给出最终的优化函数:
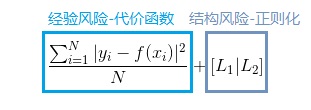
即经验结构风险的度量函数,该函数就被称为目标函数(Object function)。这个时候再回过头来看图1:最左面的第1个子图的结构风险最小(模型结构最简单),但是经验风险最大(对历史数据拟合的最差);最右边的第3个子图的经验风险最小(对历史数据完全拟合),但是结构风险最大(模型结构最复杂);中间的即第2个子图,达到了二者的良好平衡,即经验结构最小化,最适合用来预测未知数据集。
虽然上文对损失函数(Loss function)、代价函数(Cost function)、目标函数有介绍,但在很多情况下,甚至包括学术论文里,对损失函数、代价函数、目标函数的叫法区分并不严格,可能存在混用的情况,但如果三个名词同时出现,还是应该按上述定义理解,这里再总结一下:
- 损失函数
,一般是针对单个样本 i
- 代价函数
,一般是针对总体,即在损失函数基础上的总体样本均值
- 目标函数
,即在代价函数基础上加正则化项
四、算法
高中知识告诉我们,通常来说,最小值必然是极值点,而连续函数的极值点可以通过求一阶导数并令导数等于0,最后找到值最小的极值点,就是最小值点。而在机器学习中,由于目标函数的复杂性,高中的解法绝大多数情况行不通,这个时候需要一些别的算法。机器学习求解目标函数常用的算法有最小二乘法、梯度下降法(属于迭代法的一种),最小二乘法针对线性模型,而梯度下降法适用于任意模型,适用最为广泛。
4.1 最小二乘法
在一些最优化问题中,比如曲线拟合,目标函数由若干函数的平方和构成,一般可以写成
把极小化 F(x) 称为最小二乘问题。最小二乘法分为线性最小二乘问题和非线性最小二乘问题,解决线性最小二乘问题的最常用方法就是最小二乘法。
还记得高中课本里关于线性回归(线性拟合)的某一节中不要求掌握的公式吗?对于坐标为(x,y)的n个样本,假设拟合直线为y=ax+b, 通过使最小,然后对a和b分别求偏导,得到的了a和b关于n个样本的表示,这种方法就叫做最小二乘法,这是一种基于高斯分布假设的回归方法,具体以后的文章再细说。
4.2 迭代法,特别是梯度下降法
迭代法家族还有多个著名成员:机器学习中最常见的梯度下降(Gradient descent method, GD)法一族;牛顿法(Newton iteration method)一族,包括原始的牛顿法、高斯-牛顿法(Gauss-Newton iteration method, GN)、莱文贝格-马夸特方法(Levenberg-Marquardt method, LM),在实际应用中,牛顿法一族通常只用于解决最小二乘问题;拟牛顿法一族,包括DFP算法(以三个人名的首字母命名),BFGS(以四个人名的首字母命名)、L-BFGS(Limited-memory BFGS算法)。
梯度下降法(GD) 是机器学习中最常见的迭代方法:梯度是上升最快的方向,那么如果逆着上升最快的方向就是此刻下降最快的方向,所以GD通常也称最速下降法(Steepest descent method),迭代公式为 ,其中
叫学习率(Learning rate,后面会经常接触)。梯度下降法由于可对任意函数求最优解,故在机器学习中广泛使用;但GD也有如下明显的缺点:
- 从上面迭代公式可以看到,GD是线性收敛,所以收敛速度较慢;
- 当目标为非凸函数时,GD求得的解不保证是全局最优解。
,针对GD的缺点,梯度下降法扩展出了多个子类别。我们将在《机器学习·总览篇VIII 三要素之算法》一文中将对梯度下降法一族进行详细的介绍。
五、小结
机器学习 = 模型 + 策略 + 算法
在后面的文章中,有以下两个建议:
-
在对模型、策略、算法中的某一要素进行介绍时,建议用联系的思想,考虑另外两个要素与该要素的关联;
-
在对某一种特定机器学习方法进行介绍时,建议从更高的层次,考虑该机器学习方法的三要素分别是什么,为什么是这样,是否有其它可替换的方法。
参考文献
- 《统计学习方法》 李航
- AY Ng. On Discriminative vs. Generative classifiers: A comparison of logistic regression and naive Bayes. 2002
- Hung-yi Li. Course ML. 2016
- 胡海波, 李苏平. 概率模型和非概率模型在结构可靠性分析中的比较[J]. 2015(8):428-428.