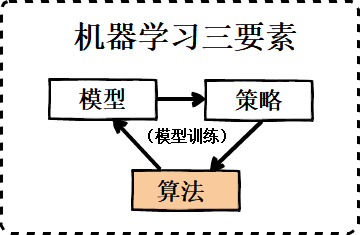
在机器学习中,与梯度下降法一样,牛顿法与拟牛顿法在解决目标函数的最优化问题方面也起着重要的作用。本篇是机器学习三要素之算法的第二篇,也是三要素介绍的最后一篇。最近的5篇文章完整地介绍了机器学习的三要素,对三要素的掌握对于机器学习的学习至关重要,所有机器学习方法的想法和实现都离不开这三个要素。
算法。文章首发于我的博客,转载请保留链接 ;)
与梯度下降法一样,在解决机器学习目标函数的最优化问题时,牛顿法与拟牛顿法也起着重要的作用。本文将分三节分别介绍 牛顿法一族、拟牛顿法一族 以及 两者与梯度下降法的比较。另外,本文涉及到的迭代公式比较抽象,难以用几何表示,所以更多的是公式推导。
一、牛顿法
1.1 原始的牛顿法(Newton’s method)
用于求方程解
牛顿法用于求方程解,即问题时,首先是设定初始值
,获得此处的导数
,计算下一个 x 值,
,重复以下迭代过程,
上述公式就是牛顿法的迭代公式,wiki 动图可以形象表示出牛顿法的迭代过程,如图1所示,
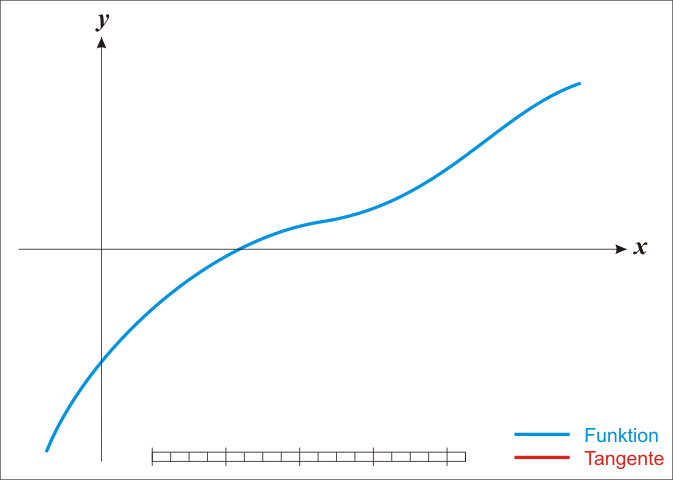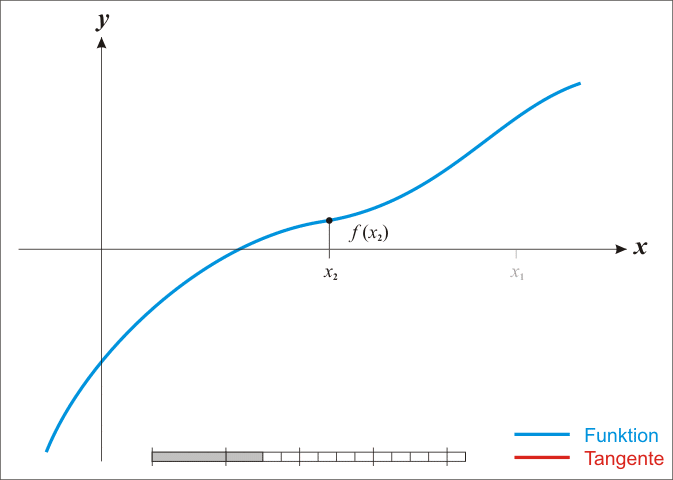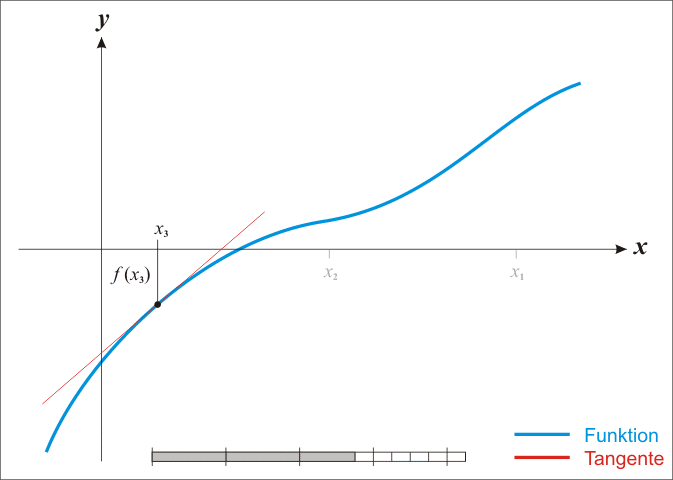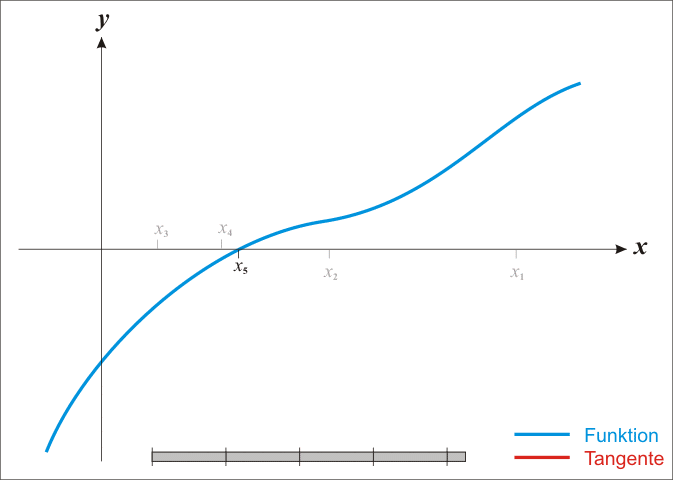
简单地介绍一下牛顿法迭代公式的推导过程,首先将方程泰勒展开,
,忽略二次以上的项,
两边对 x 求导,注意 x0 相关的值当作常量处理,
根据微积分的性质,f(x) 取最小值时,有 f′(x)=0 ,代入上面的式子有
从推导公式就可以看出,牛顿法不是全局收敛,而是局部收敛的,即需要初始值不要离最优值过远。
用于最优化问题
当牛顿法用于机器学习的最优化问题时,目标是求解 ,可以类比于求方程解,迭代公式为
当函数输出为1维时,L’(θ)为 L 关于 θ 的梯度向量,而当函数输出为 m 维时,即,则 L’(θ) 是 L 关于 θ 的一阶偏导构成的矩阵,该矩阵在19世纪初由德国数学家雅可比提出且被命名为雅可比矩阵 ,θ 表示成向量形式
,则雅可比矩阵表示为
是函数 L 关于 θ 的二阶偏导构成的矩阵,类似于雅可比矩阵,该矩阵在19世纪由德国数学家海森提出且被命名为海森矩阵,海森矩阵表示为
,将雅可比矩阵 J 和海森矩阵 H 带入原迭代公式,由于在迭代公式的迭代量中,海森矩阵是除数,所以实际上是乘以海森矩阵的逆,迭代公式可表示为
优点:二阶收敛,收敛速度快
二阶收敛的牛顿法相比于一阶收敛的梯度下降法,收敛速度更快,因为二阶收敛还额外考虑了下降速度变化的趋势。从几何上解释,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径,路径找对了,下降速度就更快。
缺点:难以计算
牛顿法的迭代过程中,每一步都需要求解目标函数的 Hessian 矩阵的逆矩阵,计算比较复杂甚至是无法计算,这个问题很严重,所以在机器学习中甚至都不会直接使用牛顿法。
1.2 高斯-牛顿法(Gauss-Newton algorithm,GN)
GN 是牛顿法求解最小二乘问题时的派生出的特殊求解方法。回顾一下牛顿法的迭代公式,
其中,对于最小二乘问题,L 是如下形式,
其中 r 为最小二乘问题的残差,即 L 函数值与 groudtruth 的差值。L 关于 θ 的雅可比矩阵 J 和海森矩阵 H 可用 r 表示为
高斯牛顿法(GN)通过舍弃用海森矩阵的二阶偏导数实现,即忽略上式中 H 的第二项,也就有了对海森矩阵的近似计算,
带入到牛顿法的迭代公式,则 GN 的迭代公式表示为
优点:计算量小
原始的牛顿法主要问题是 Hessian 矩阵 H 中的二阶信息项通常难以计算或者花费的工作量很大,GN 对此做了针对性的改进,利用在计算梯度时已经得到一阶偏导 J,这样 H 中的一阶信息项几乎是现成的,鉴于此,为了简化计算,我们可用一阶导数信息逼近二阶信息项。注意这么干的前提是,残差 r 接近于零或者接近线性函数从而接近与零时,二阶信息项才可以忽略,通常称为“小残量问题”,最典型的就是最小二乘问题,否则高斯牛顿法不收敛。
缺点:收敛要求较为严格
对于残量 r 值较大的问题,收敛速度较慢;对于残量很大的问题,不收敛;不能保证全局收敛。这里稍微解释一下全局收敛和局部收敛:收敛性与初始点无关,则是全局收敛;当初值靠近最优解时才收敛,则是局部收敛;牛顿法和 GN 都是局部收敛。
1.3 莱文贝格-马夸特方法(Levenberg–Marquardt algorithm,LM)
LM 同时结合了梯度下降法(GD)稳定下降的优点和高斯牛顿法(GN)在极值点附近快速收敛的优点,同时避免了 GD 和 GN 相应的缺点。GN 的迭代公式为
。而在 LM 方法的迭代公式为
,从 LM 的公式中可以看到,λ 大的时候这种算法会接近 GD(梯度下降法),小的时候会接近 GN(高斯牛顿法) 。在 LM 的实际应用中,为了保证能快速稳定下降,通常会根据 L 函数值真实减少量与预测减少量 ρ 来动态调整 λ :
- 当 0 < ρ < 阈值,说明游走在刀刃上,则不改变 λ ;
- 当 ρ > 阈值,说明近似效果很好,则增大 λ;
- 当 L 函数值是增加,即 ρ < 0,说明近似效果很差,则减小 λ。
二、拟牛顿法(Quasi-Newton Methods)
拟牛顿法的本质思想是在牛顿法的基础上,使用迭代法来获得 Hessian 矩阵的逆矩阵 :这样一来,只需要最开始求一次逆,后面就可以通过迭代的方法来获取每一次需要使用的 Hessian 矩阵的逆矩阵,从而简化了迭代运算的复杂度。
拟牛顿法于20世纪50年代由美国 Argonne 国家实验室的物理学家 W.C.Davidon 所提出来,这种算法在当时看来是非线性优化领域最具创造性的发明之,而且随后该算法被证明远比其他方法快速和可靠,使得非线性优化这门学科在一夜之间突飞猛进。机器学习中常见的拟牛顿法有 DFP 法、BFGS 法、 L-BFGS法。
那么拟牛顿法一族,包括DFP 法、BFGS 法、 L-BFGS法,是如何构造 Hessian 矩阵的逆矩阵的迭代公式呢?回到1.1节中牛顿法迭代公式的推导过程,二阶泰勒展开式对 x 进行求导得
将 带入公式再变换一下得
令 ,则迭代公式可以简单表示为
接下来的3种方法就是围绕这个式子来构造 Hessian 矩阵的逆矩阵的迭代公式。
1.1 DFP法(Davidon-Fletcher-Powell algorithm)
DFP 法的核心思想是直接构造 Hessian 矩阵的逆矩阵的迭代公式。继续上文公式的推导,先假设海森矩阵的逆矩阵的迭代公式为 ,DFP 法的目标就是求这个
,将
代入上式得
然后假设,代入上式得
令 使上式满足,则有
整合上述 u, v, α, β 相关的表达式,带入到 Hessian 矩阵的逆矩阵的迭代公式,得
1.2 BFGS法(Broyden–Fletcher–Goldfarb–Shanno algorithm)
BFGS 算法与 DFP 算法的区别在于,迭代公式结果不一样,对 Hessian 矩阵的逆矩阵的构造方法也不一样:其中,DFP算法是直接构造,而BFGS是分两步走:先求 Hessian 矩阵的迭代公式,然后根据Sherman-Morrison公式转换成Hessian 矩阵的逆矩阵的迭代公式。
首先求 Hessian 矩阵的迭代公式,虽然 DFP 法求得是 Hessian 逆矩阵的迭代公式,但其实可以用同样的推导过程求 Hessian 矩阵的迭代公式,得到
然后根据 Sherman-Morrison 公式,即对于任意 n x n 的 非奇异矩阵 ,u、v 都是 n 维向量,若 ,则
该公式描述了在矩阵 A 发生某种变化时,如何利用之前求好的逆,求新的逆,而这个性质正是我们需要的,接下来通过该式子将 Hessian 矩阵的迭代公式改造一下,得到 Hessian 矩阵的逆矩阵的迭代公式
以上过程看起来是“多此一举”,但事实上这种 BFGS 的近似方法相比于 DFP 会带来额外的优势,如下文所述。
优点
BFGS 法相比于 DFP 法,对Hessian 矩阵的逆矩阵近似误差更小,这是因为 BFGS 具有自校正的性质(self-correcting property)。通俗来说,如果某一步 BFGS 对 Hessian矩阵的逆矩阵估计偏了,导致优化变慢,那么 BFGS 会在较少的数轮迭代内校正。对证明感兴趣可以参考《A Tool for the Analysis of Quasi-Newton Methods with Application to Unconstrained Minimization》。
缺点
拟牛顿法都共同具有的缺点,即对 Hessian 矩阵的逆矩阵的近似存在误差,但 BFGS 相比与 DFP 好一点;BFGS 和 DFP 都吃内存,因为都需要存储 Hessian 矩阵的逆矩阵。
1.3 L-BFGS法(Limited-memory Broyden–Fletcher–Goldfarb–Shanno algorithm)
L-BFGS 法是针对 BFGS 算法吃内存问题的一个小改进,本质是用准确度下降的少量代价来换取大量空间的节省,它对 BFGS 算法进行了近似,不存储完整的逆矩阵。回顾一下 BFGS 的迭代公式,
L-BFGS 不存储逆矩阵,而是存储最新 m 个上面公式中的 s 和 y 向量,即 ,从而使存储空间复杂度开销从
降低到
。
三、梯度下降法、牛顿法、拟牛顿法的比较
梯度下降法一族(如 SGD、各种 Adaptive SGD)、牛顿法一族(如 Gauss-Newton Method,LM 法)、拟牛顿法一族(如 DFP 法、L-BFGS 法)是机器学习中最常见的三大类迭代法。用表格可以直观地对比较三种迭代大类的差别,分别从 迭代公式 、收敛性 、在机器学习中擅长的应用场景 以及 在实际应用中最具代表性的实现,这4个角度进行比较,如下所示,
| 迭代公式 | 收敛性 | 擅长场景 | 应用代表 | |
|---|---|---|---|---|
| 梯度下降法 | 全局收敛、一阶收敛 | 神经网络 | SGD、RMSprop、Adam | |
| 牛顿法 | 局部收敛、二阶收敛 | 非线性最小二乘问题 | LM 法 | |
| 拟牛顿法 | 局部收敛、二阶收敛 | 逻辑回归 | L-BFGS |
事实上,在机器学习实际应用中,梯度下降法(比如SGD),特别是自适应学习率的梯度下降法(比如RMSprop、Adam)更实用也更常用,应用局限性也最低,在更多的情况下能稳定收敛。
至此,最近的5篇文章完整地介绍了机器学习的三要素,对三要素的掌握对于机器学习的学习至关重要,所有机器学习方法的想法和实现都离不开这三个要素。
参考文献
- wiki: 牛顿法
- wiki: Levenberg-Marquardt方法
- wiki: 海森矩阵
- wiki: 雅可比矩阵
- csdn: Levenberg-Marquardt算法浅谈
- zhihu: DFP与BFGS算法的比较?
- zhihu: 梯度下降or拟牛顿法?
- csdn: 最全的机器学习中的优化算法介绍
- csdn:Gauss-Newton算法学习
- csdn: 优化算法——拟牛顿法之DFP算法
- csdn: 拟牛顿法(DFP、BFGS、L-BFGS)
- cnblog: 常见的几种最优化方法